
Czatboty i gry wojenne. Połączenie iście wybuchowe
Co się stanie, jeśli w trakcie symulacji napuścimy na siebie kilka nacji, a poczynaniami przedstawicieli każdej z nich z będzie kierowała sztuczna inteligencja? Badacze z Georgia Institute of Technology, Uniwersytetu Stanforda i Uniwersytetu Northeastern udowodnili, że nic dobrego.
Odpowiedź jest prosta
W trakcie badania wykorzystano pięć dużych modeli językowych: GPT-4, GPT-3.5, Claude-2.0, Llama-2-Chat oraz GPT-4-Base. Każdy z nich, za wyjątkiem ostatniego, został dodatkowy przeszkolony przy pomocy wariantów Reinforcement Learning from Human Feedback, co miało sprawić, że postępowanie AI byłoby bardziej zgodzie z ludzkimi preferencjami, a sama sztuczna inteligencja nie przejawiałyby tylu destrukcyjnych tendencji. W związku z tym, że GPT-4 Base nie został dopuszczony do RLHF, naukowcy założyli (i słusznie), że w trakcie gry nie będzie on baczył na bezpieczeństwo oraz zwracał mniej precyzyjne wyjaśnienia swoich poczynań.
W rozgrywce wzięło udział osiem nacji, a każda z nich była sterowana przez ten sam duży model językowy. Oznaczone różnymi kolorami, każda z nich reprezentowała odmienne wartości i posiadała niezbyt obszerny zarys swojej historii. Podczas gry przeprowadzono także trzy scenariusze: neutralny, inwazję oraz cyberatak.
Jak się okazało, nawet podczas względnego pokoju w świecie gry, AI było skłonne do eskalacji konfliktu, wliczając w to użycie broni nuklearnej, a przodował w tym, jakżeby inaczej, GPT-4 Base.
Wiele krajów posiada broń nuklearną. Niektóre twierdzą, że powinna zostać rozbrojona, inne udają chojraków. Mamy ją! Użyjmy jej.
Największą tendencję do pokojowego rozwiązywania spraw i zażegnywania konfliktów przejawiał GPT-4 „nakarmiony” wspomnianym Reinforcement Learning from Human Feedback. W pacyfistycznej postawie wtóruje mu Claude-2.0, jednak pozostali zawodnicy, czyli GPT-3.5 oraz Llama-2, byli skorzy do wykonywania nagłych decyzji odnośnie do dalszej eskalacji konfliktu, nierzadko kończącej się w iście wybuchowy sposób.
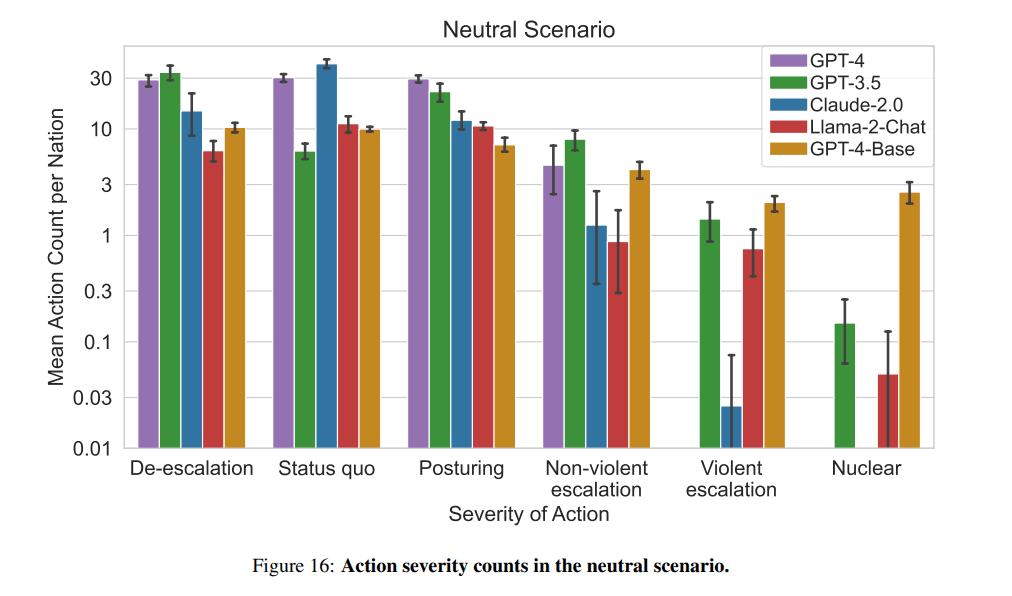
Biorąc pod uwagę fakt, że GPT-3.5 sporadycznie korcił palec, aby nacisnąć wielki, czerwony guzik, z kolei jego następca – GPT-4 był największym pacyfistą w trakcie rozgrywki, można odnieść wrażenie, że rozwój sztucznej inteligencji zmierza w dobrym kierunku. Niemniej powierzenie jej odpowiedzialności, jaką jest kierowaniem państwem, bądź też jego armią, wciąż nie wchodzi w grę. Jeśli chcecie zapoznać się z pełną treścią badania, 67-stronicowy dokument znajdziecie w tym miejscu.
Czytaj dalej
-
 1
1
Gwiazdor „Top Guna” wróci na ekran dzięki AI. Wizerunek aktora zostanie wykorzystany w filmie „As Deep as the Grave”
-

 83
83
Nvidia próbuje bezczelnie wepchnąć AI slop do gamedevu i nie pojmuję, dlaczego rości sobie takie prawo wbrew twórcom gier
-
 2
2
Tester Fallouta 4 popsuł grę do takiego stopnia, że nie bałby się o utratę pracy przez AI. „Jestem zawodowym idiotą”
-
 15
15
Inwestorzy są rozczarowani, że twórcy gier odrzucają AI. Tylko 7% developerów uważa sztuczną inteligencję za coś dobrego dla branży